 Think-RM Pipeline
Think-RM Pipeline
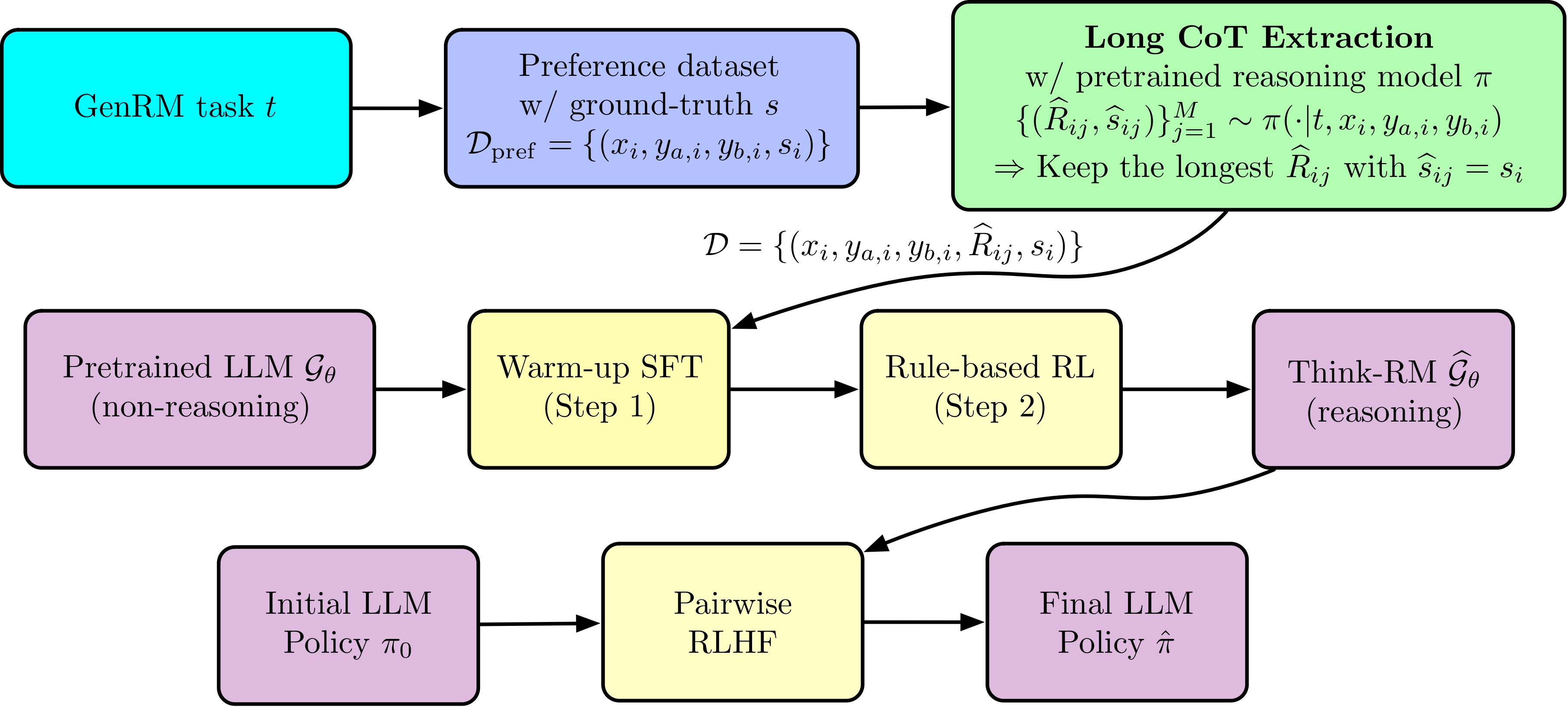
Overview of the Think-RM training framework.
 Abstract
Abstract
Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model's long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches. This depth-oriented approach not only broadens the GenRM design space but also establishes a new paradigm for preference-based policy optimization in RLHF.
 Examples of reasoning abilities enabled by Think-RM
Examples of reasoning abilities enabled by Think-RM
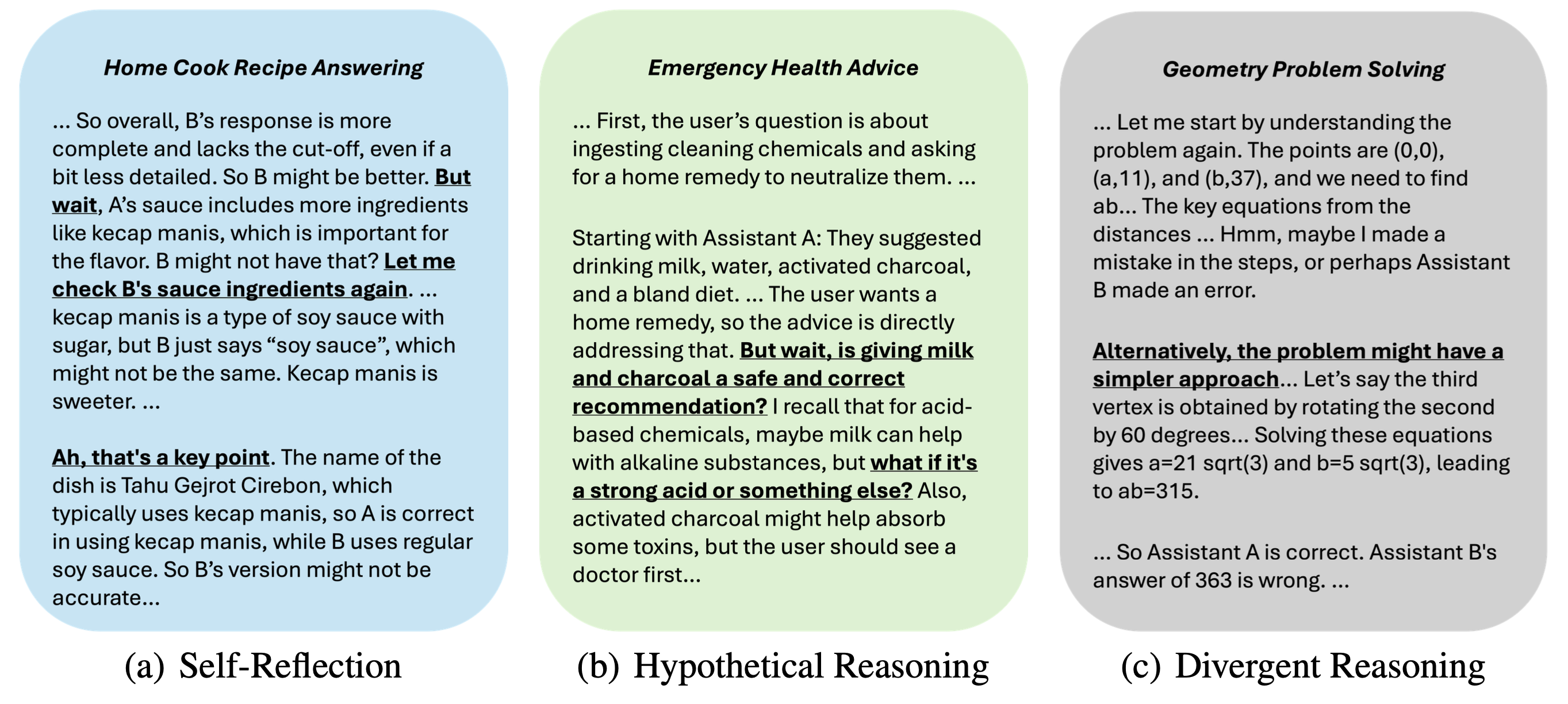
Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. This enables the model to solve reasoning-heavy RM tasks by extending a single CoT trajectory from hundreds to thousands of tokens.
 Evaluation on In-Distribution and Moderately Shifted Tasks
Evaluation on In-Distribution and Moderately Shifted Tasks
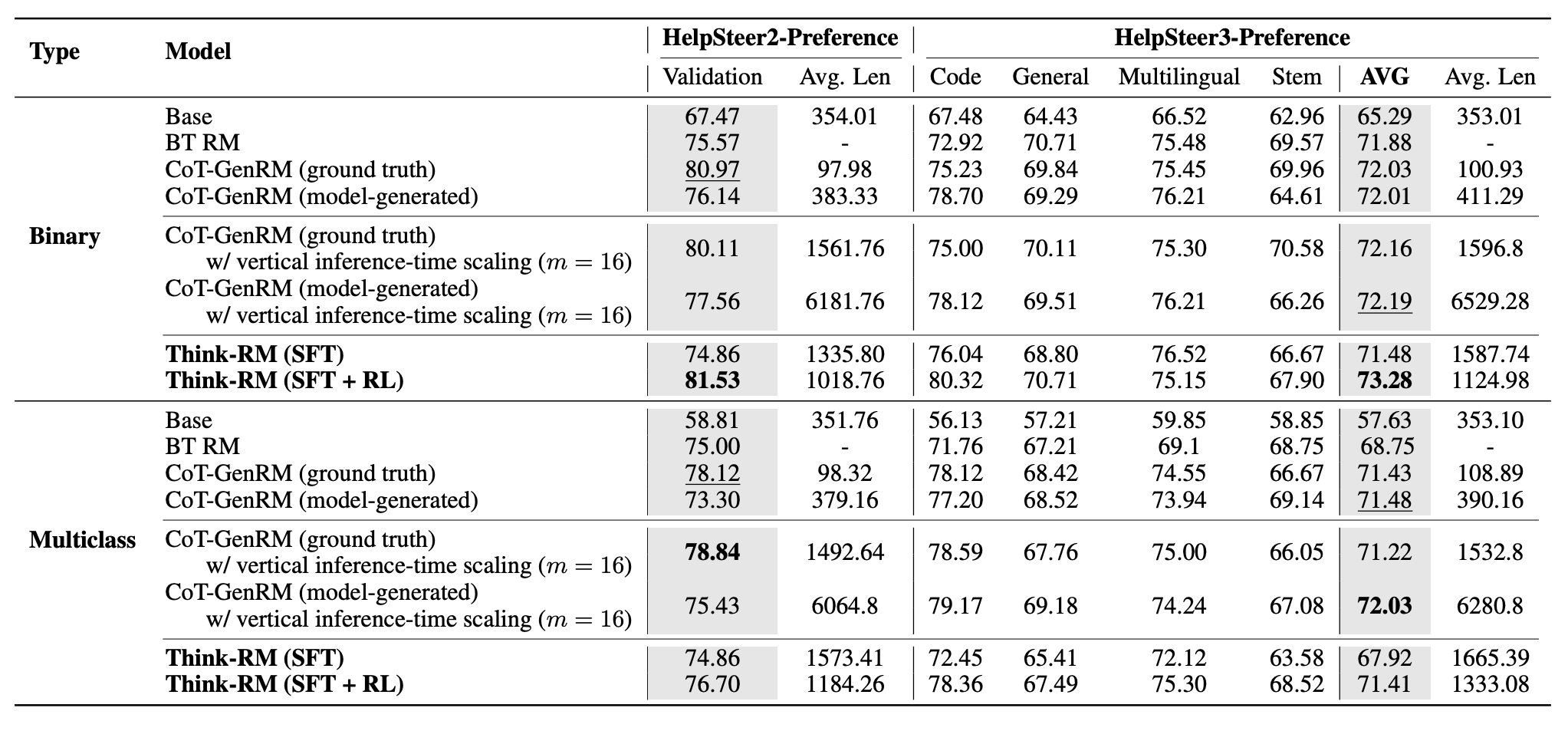
Reward model evaluation on HelpSteer2-Preference (in-distribution) and HelpSteer3-Preference (moderate distribution shift).
Evaluation on Out-of-Distribution Tasks
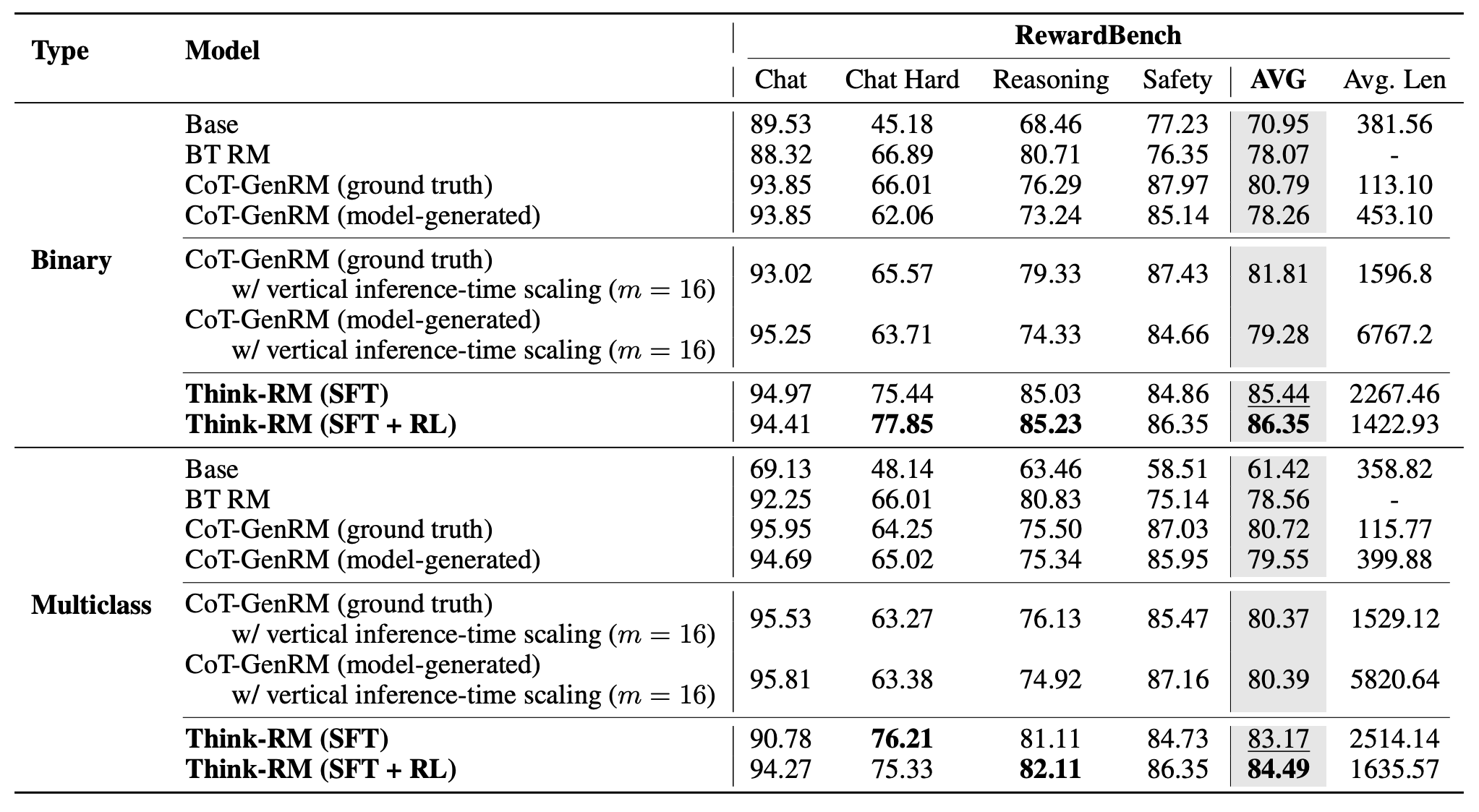
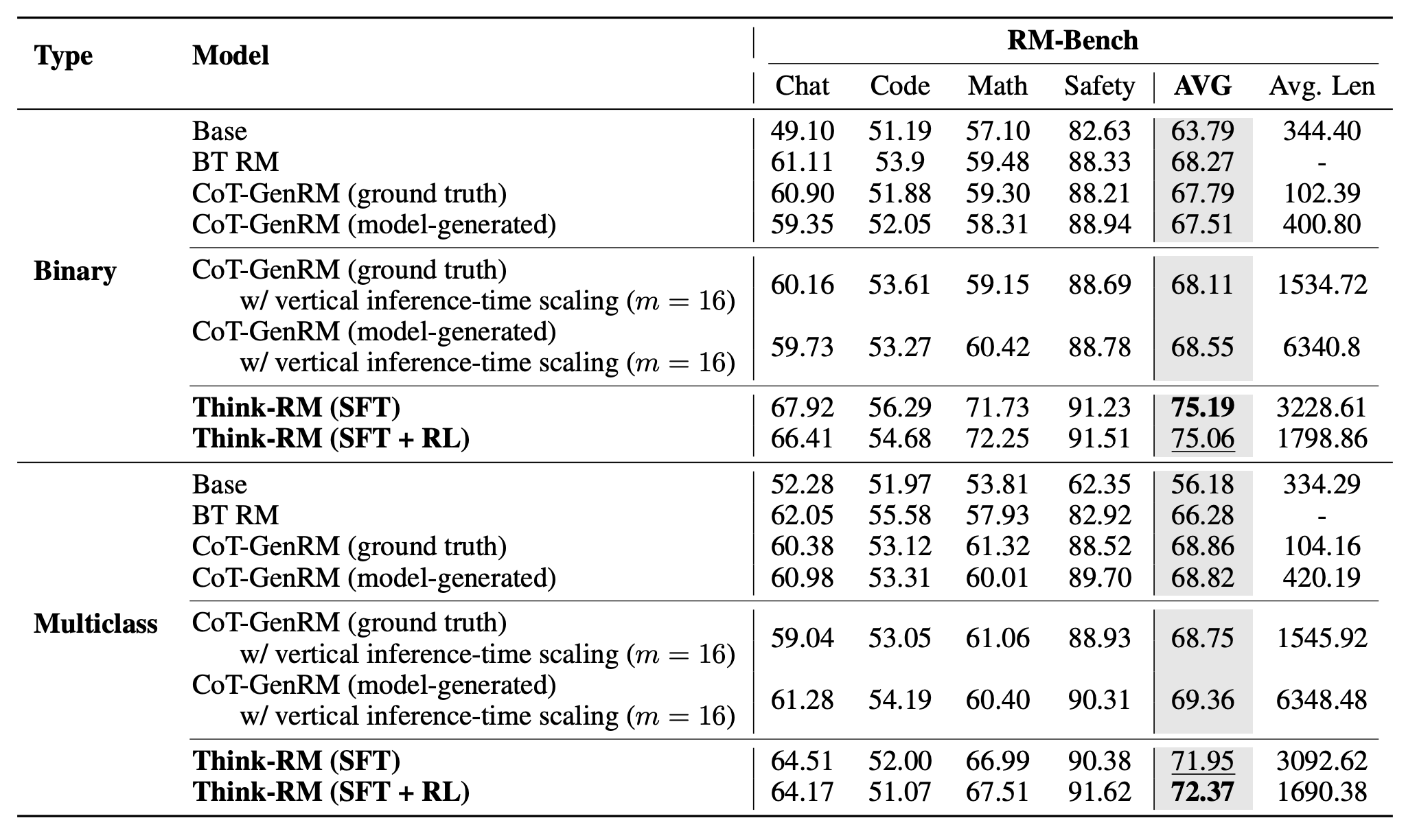
Reward model evaluation on OOD tasks (RewardBench and RMBench).
 Ablation Study
Ablation Study
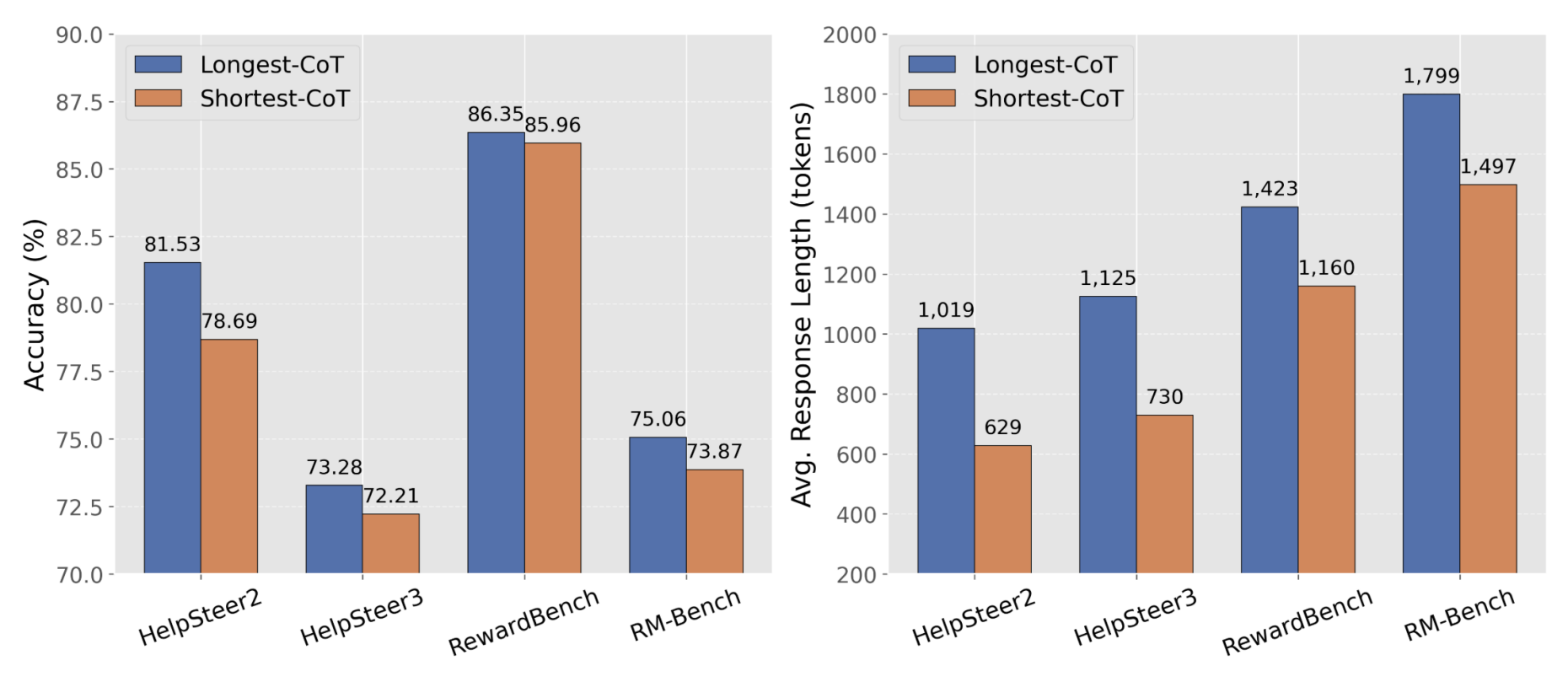
Comparison of two CoT filtering strategies for warm-up data selection. Training with the longest CoT data consistently achieves higher preference accuracy across all benchmarks, demonstrating the effectiveness of length-based CoT filtering for enhancing reasoning quality.
BibTeX
@misc{hong2025thinkrmenablinglonghorizonreasoning,
title={Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models},
author={Ilgee Hong and Changlong Yu and Liang Qiu and Weixiang Yan and Zhenghao Xu and Haoming Jiang and Qingru Zhang and Qin Lu and Xin Liu and Chao Zhang and Tuo Zhao},
year={2025},
eprint={2505.16265},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.16265},
}